[From the early days of Cliff Nass’ Computers Are Social Actors (CASA) research we’ve noted drivers’ social responses to cars as well, due largely to their direct, haptic interaction with their vehicles. Voice-based GPS navigation systems added another set of cues to enhance Cars As Social Actors perceptions and responses. But this interesting story from IEEE Spectrum
describes the next level of this form of Medium As Social Actor (MASA) presence created by an evolving vehicle-based AI that provides real-time, context-dependent guidance in a more natural, conversational manner that humans can better understand, and trust. See the original story for three more images and a 4:07 minute video (also available via YouTube
). –Matthew]
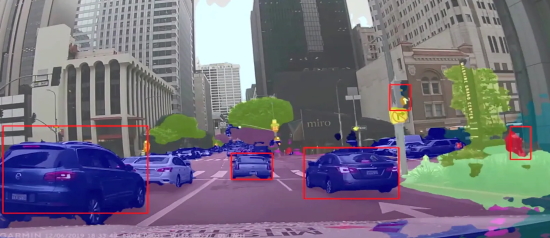
[Image: Rather than tell the driver that there’s an intersection 30 meters ahead, the navigation system refers to landmarks, such as the crosswalk in this illustration, or a tree farther down the street. Credit: Mitsubishi Electric Research Laboratories]
At Last, A Self-Driving Car That Can Explain Itself
Mitsubishi’s Ai Not Only Improves Performance, It Also Fosters Trust
By Chiori Hori and Anthony Vetro
February 23, 2022
For all the recent improvements in artificial intelligence, the technology still cannot take the place of human beings in situations where it must frame its perceptions of the world in words that people can understand.
You might have thought that the many apparent advances in speech recognition would have solved the problem already. After all, Apple’s Siri, Microsoft’s Cortana, Amazon’s Alexa and Google Home are all very impressive, but these systems function solely on voice input: They can’t understand or react to the environment around them.
To bridge this communications gap, our team at Mitsubishi Electric Research Laboratories has developed and built an AI system that does just that. We call the system scene-aware interaction, and we plan to include it in cars.
As we drive down a street, in downtown Los Angeles, our system’s synthesized voice provides navigation instructions. But it doesn’t give the sometimes hard-to-follow directions you’d get from an ordinary navigation system. Our system understands its surroundings and provides intuitive driving instructions, the way a passenger sitting in the seat beside you might do. It might say, “Follow the black car to turn right” or “Turn left at the building with a billboard.” The system will also issue warnings, for example: “Watch out for the oncoming bus in the opposite lane.”
To support improved automotive safety and autonomous driving, vehicles are being equipped with more sensors than ever before. Cameras, millimeter-wave radar, and ultrasonic sensors are used for automatic cruise control, emergency braking, lane keeping, and parking assistance. Cameras inside the vehicle are being used to monitor the health of drivers, too. But beyond the beeps that alert the driver to the presence of a car in their blind spot or the vibrations of the steering wheel warning that the car is drifting out of its lane, none of these sensors does much to alter the driver’s interaction with the vehicle.
Voice alerts offer a much more flexible way for the AI to help the driver. Some recent studies
have shown that spoken messages are the best way to convey what the alert is about and are the preferable option in low-urgency driving situations. And indeed, the auto industry is beginning to embrace technology that works in the manner of a virtual assistant. Indeed, some carmakers have announced plans to introduce conversational agents that both assist drivers with operating their vehicles and help them to organize their daily lives.
The idea for building an intuitive navigation system based on an array of automotive sensors came up in 2012 during discussions with our colleagues at Mitsubishi Electric’s automotive business division in Sanda, Japan. We noted that when you’re sitting next to the driver, you don’t say, “Turn right in 20 meters.” Instead, you’ll say, “Turn at that Starbucks on the corner.” You might also warn the driver of a lane that’s clogged up ahead or of a bicycle that’s about to cross the car’s path. And if the driver misunderstands what you say, you’ll go on to clarify what you meant. While this approach to giving directions or guidance comes naturally to people, it is well beyond the capabilities of today’s car-navigation systems.
Although we were keen to construct such an advanced vehicle-navigation aid, many of the component technologies, including the vision and language aspects, were not sufficiently mature. So we put the idea on hold, expecting to revisit it when the time was ripe. We had been researching many of the technologies that would be needed, including object detection and tracking, depth estimation, semantic scene labeling, vision-based localization, and speech processing. And these technologies were advancing rapidly, thanks to the deep-learning revolution.
Soon, we developed a system that was capable of viewing a video and answering questions about it. To start, we wrote code that could analyze both the audio and video features of something posted on YouTube and produce automatic captioning for it. One of the key insights from this work was the appreciation that in some parts of a video, the audio may be giving more information than the visual features, and vice versa in other parts. Building on this research, members of our lab organized the first public challenge on scene-aware dialogue in 2018, with the goal of building and evaluating systems that can accurately answer questions about a video scene.
We then decided it was finally time to revisit the sensor-based navigation concept. At first we thought the component technologies were up to it, but we soon realized that the capability of AI for fine-grained reasoning about a scene was still not good enough to create a meaningful dialogue.
Strong AI that can reason generally is still very far off, but a moderate level of reasoning is now possible, so long as it is confined within the context of a specific application. We wanted to make a car-navigation system that would help the driver by providing its own take on what is going on in and around the car.
One challenge that quickly became apparent was how to get the vehicle to determine its position precisely. GPS sometimes wasn’t good enough, particularly in urban canyons. It couldn’t tell us, for example, exactly how close the car was to an intersection and was even less likely to provide accurate lane-level information.
We therefore turned to the same mapping technology that supports experimental autonomous driving, where camera and lidar (laser radar) data help to locate the vehicle on a three-dimensional map. Fortunately, Mitsubishi Electric has a mobile mapping system that provides the necessary centimeter-level precision, and the lab was testing and marketing this platform in the Los Angeles area. That program allowed us to collect all the data we needed.
A key goal was to provide guidance based on landmarks. We knew how to train deep-learning models to detect tens or hundreds of object classes in a scene, but getting the models to choose which of those objects to mention—”object saliency”—needed more thought. We settled on a regression neural-network model that considered object type, size, depth, and distance from the intersection, the object’s distinctness relative to other candidate objects, and the particular route being considered at the moment. For instance, if the driver needs to turn left, it would likely be useful to refer to an object on the left that is easy for the driver to recognize. “Follow the red truck that’s turning left,” the system might say. If it doesn’t find any salient objects, it can always offer up distance-based navigation instructions: “Turn left in 40 meters.”
We wanted to avoid such robotic talk as much as possible, though. Our solution was to develop a machine-learning network that graphs the relative depth and spatial locations of all the objects in the scene, then bases the language processing on this scene graph. This technique not only enables us to perform reasoning about the objects at a particular moment but also to capture how they’re changing over time.
Such dynamic analysis helps the system understand the movement of pedestrians and other vehicles. We were particularly interested in being able to determine whether a vehicle up ahead was following the desired route, so that our system could say to the driver, “Follow that car.” To a person in a vehicle in motion, most parts of the scene will themselves appear to be moving, which is why we needed a way to remove the static objects in the background. This is trickier than it sounds: Simply distinguishing one vehicle from another by color is itself challenging, given the changes in illumination and the weather. That is why we expect to add other attributes besides color, such as the make or model of a vehicle or perhaps a recognizable logo, say, that of a U.S. Postal Service truck.
Natural-language generation was the final piece in the puzzle. Eventually, our system could generate the appropriate instruction or warning in the form of a sentence using a rules-based strategy.
Rules-based sentence generation can already be seen in simplified form in computer games in which algorithms deliver situational messages based on what the game player does. For driving, a large range of scenarios can be anticipated, and rules-based sentence generation can therefore be programmed in accordance with them. Of course, it is impossible to know every situation a driver may experience. To bridge the gap, we will have to improve the system’s ability to react to situations for which it has not been specifically programmed, using data collected in real time. Today this task is very challenging. As the technology matures, the balance between the two types of navigation will lean further toward data-driven observations.
For instance, it would be comforting for the passenger to know that the reason why the car is suddenly changing lanes is because it wants to avoid an obstacle on the road or avoid a traffic jam up ahead by getting off at the next exit. Additionally, we expect natural-language interfaces to be useful when the vehicle detects a situation it has not seen before, a problem that may require a high level of cognition. If, for instance, the car approaches a road blocked by construction, with no clear path around it, the car could ask the passenger for advice. The passenger might then say something like, “It seems possible to make a left turn after the second traffic cone.”
Because the vehicle’s awareness of its surroundings is transparent to passengers, they are able to interpret and understand the actions being taken by the autonomous vehicle. Such understanding has been shown to establish a greater level of trust and perceived safety.
We envision this new pattern of interaction between people and their machines as enabling a more natural—and more human—way of managing automation. Indeed, it has been argued that context-dependent dialogues are a cornerstone of human-computer interaction.
Cars will soon come equipped with language-based warning systems that alert drivers to pedestrians and cyclists as well as inanimate obstacles on the road. Three to five years from now, this capability will advance to route guidance based on landmarks and, ultimately, to scene-aware virtual assistants that engage drivers and passengers in conversations about surrounding places and events. Such dialogues might reference Yelp reviews of nearby restaurants or engage in travelogue-style storytelling, say, when driving through interesting or historic regions.
Truck drivers, too, can get help navigating an unfamiliar distribution center or get some hitching assistance. Applied in other domains, mobile robots could help weary travelers with their luggage and guide them to their rooms, or clean up a spill in aisle 9, and human operators could provide high-level guidance to delivery drones as they approach a drop-off location.
This technology also reaches beyond the problem of mobility. Medical virtual assistants might detect the possible onset of a stroke or an elevated heart rate, communicate with a user to confirm whether there is indeed a problem, relay a message to doctors to seek guidance, and if the emergency is real, alert first responders. Home appliances might anticipate a user’s intent, say, by turning down an air conditioner when the user leaves the house. Such capabilities would constitute a convenience for the typical person, but they would be a game-changer for people with disabilities.
Natural-voice processing for machine-to-human communications has come a long way. Achieving the type of fluid interactions between robots and humans as portrayed on TV or in movies may still be some distance off. But now, it’s at least visible on the horizon.
|